Amazon Textract Service – Extract text, data and forms from documents

Chinmoyee

Just imagine how much error-prone, repetitive, and time-consuming it would be to extract data manually from various sources/documents, which might also impact the entire business process. Let’s consider a use case where the power of Amazon Textract can be harnessed.
“A transportation agency maintains all registration and transportation in paper-based documents. With the growth of the number of documents, it requires huge manual intervention to find an old document, which has pushed business to digitalize and evolve their document processing capabilities.”
How can this use case be addressed?
- Manual Processing – Data from existing documents can be manually processed, extracted, and entered into the system. While this procedure sounds simple, it has a very high percentage of challenges, some of which are error-prone and inconsistent results, highly expensive, and slow.
- Otherwise, simple optical character recognition (OCR) techniques can also be leveraged to accelerate the data extraction process, however, this process will again require manual configuration and intervention to extract meaningful information.
Amazon Textract – The big game-changer
Leveraging the power of Machine Learning, Amazon Textract reads, and processes scanned documents and accurately identifies and extracts text, handwriting, contents of form fields, information stored in tables, and other data from the processed documents, undeterred by variability in formats of documents.
Additionally, human reviews with Amazon Augmented AI can be added to review sensitive information. Also, the analyzed data can be indexed in Amazon Elastic Search to build an intelligent search engine so that users can search specific documents/data from plenty of documents in no time.
Let’s have a quick glance at the capabilities of the Amazon Textract service.
- Detects text in a document both synchronously and asynchronously
- Analyze documents and extract data into three categories:
- Raw Text
- Forms: Form data extracted from a document in the form of key-value pairs
- Tables: Extract tables, cells, text within cell, and all these extracted data can be exported to JSON, csv or txt file
- Analyze Invoices and Receipts
Overview of How the Use Case can be Executed
- Scan documents/screenshots/pictures of registration/transportation documents/forms
- Upload the documents/files to the Amazon S3 bucket (Amazon Simple Storage Service). This can be done through a console or programmatically.
- Trigger AWS Lambda function
- The Lambda function sends the scanned documents/files to Amazon Textract for analysis.
- Amazon Textract analyzes and extracts text and data
- The extracted data is sent to Amazon elastic search index
- Leverage elastic search index to build a search engine
To visualize how data extraction is performed by Amazon Textract service, we will consider the below sample document.

Source: Google
Document analysis by Amazon Textract
- Raw text: This shows the raw lines and words extracted from the document. The extracted text can be stored in elastic search index, mapping the Amazon S3 bucket name and path to the indexed document, which can be later leveraged to search data and document.
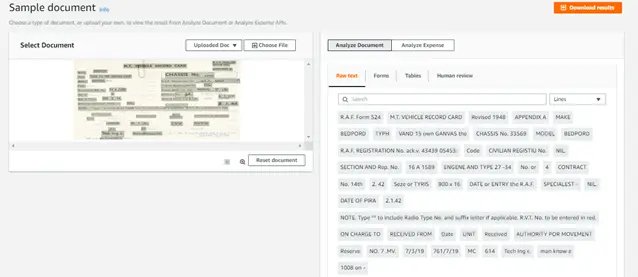
- Forms and tables: Here we can see Amazon Textract has harnessed Machine Learning to identify and extract the contents of fields in forms as well as data stored in tables. This enables and provides a powerful solution to stepped workflows.
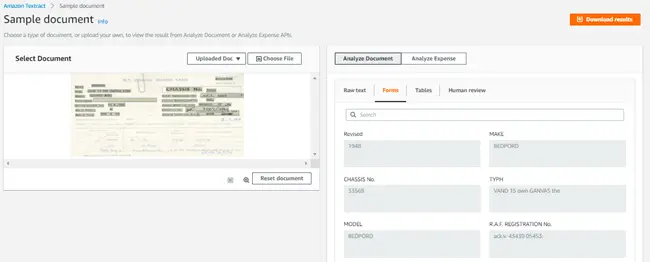
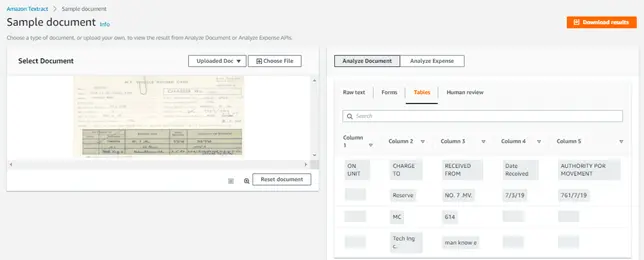
As we can see, in addition to extracting raw text from the document, Amazon Textract also recognizes form fields, tables, rows, columns and extract data from it accordingly. This clearly signifies that Amazon Textract service will highly reduce manual intervention and will create accurate outputs from various sources of documents. Intelligent search mechanisms, as well as form processing workflows, can be built and automated from the data extracted from the Amazon Textract service.