Transforming Digital Asset Management using Azure Computer Vision

Chinmoyee
Prior to diving into details, let us comprehend what’s digital asset. In the simplest terms, a digital asset is a rich media content (which includes photos, music, videos and other multimedia content) that’s stored digitally and is detailed by its metadata.
What is Digital Asset Management?
Digital asset management (DAM) is a business procedure for structuring, storing, and retrieving rich media and managing digital authorizations. It provides smart features that turn a DAM solution into a dynamic and agile platform.
There can be ample amount of use cases for DAM and quite a common use case is:
In order to avoid lot of manual intervention, designers will have a strong requisite to categorize images based on visible logos, faces, objects, colors, taxonomy, text in image, and so on to enhance their workflows to quickly search for images using metadata/categorization and reusable content.
They may want some mechanism to automate creation of tags, captions for images and attach keywords, so the images can be easily searched. Sounds interesting right!
Azure’s “Computer Vision” cognitive service comes very handy to manage the above use case! It leverages advanced machine learning algorithms that process images and provides detailed insights on the visual features and attributes on the image. Computer vision supports to replicate human perception and associated brain functions to acquire, analyze, process, and understand an image/video.
How Azure Computer Vision Powers Digital Assets Today?
Computer vision can help to visualize, analyze, and convert into actionable intelligence that can be used to enhance business outcomes. The reports generated through computer vision can help managers track business operations in real time, predict machine downtimes, minimize errors, and enhance safety and security of the critical assets.
Computer Vision is an AI service that analyses image content. Below is a high-level overview of the features and characteristics processed by Computer Vision cognitive service:
- Identifies and tags visual features in an image with a confidence score
- Provides bounding box co-ordinates with a confidence score for each object identified in the image
- Detects popular commercial brands in images by leveraging a database of thousands of global logos
- Generates taxonomy-based categories detected in an image
- Provides human-understandable complete sentence description of the image with a confidence score
- Detect human faces within an image and generates age, gender, and rectangle for each detected image
- Analyze the content type of images and indicates the probability of the image being clip art or a line drawing
- Leverages domain models (that have been trained on specialized data) to provide domain-specific analysis of an image
- Analyzes color usage for a vision to provide three different attributes with respect to color code in the image: the dominant foreground color, the dominant foreground color, and the set of dominant colors for the image as a whole
- Generates cropped and intuitive thumbnails for an image
- Provides the co-ordinates of the area of interest of an image
With all these capabilities, this is obvious that designers can leverage all the features provided by “Computer Vision” service to process and analyze the images, and accordingly the output can be used to tag and attach keyword/metadata to the images, which will then provide great flexibility to search images with the keywords.
How about we consider an image for instance and have a high-level dive to the highlights?

As part of the example above, we are using visual feature type for Description, Categories, Tags and Brands. Let us have an eye on the outputs of the image based on the visual features specified below:
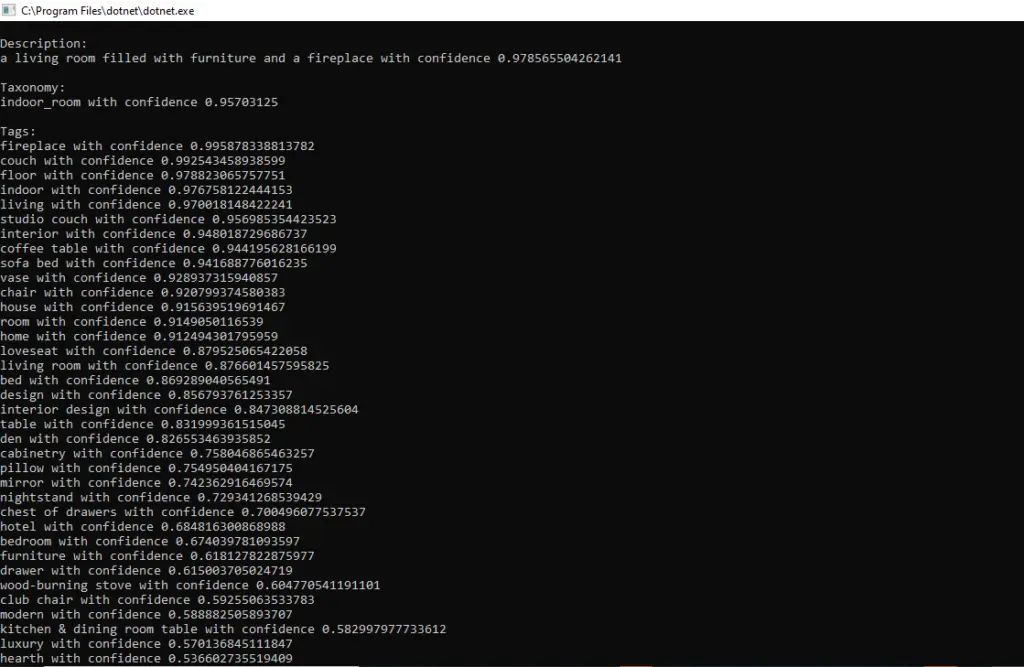
Doesn’t the output report look very encouraging? As described in the top section, we can see the service has generated entire description of the image in human-readable language, using complete sentence. Similarly, the taxonomy/categorization and tags are detailed down with great confidence percentage. Another interesting piece is identification of the brand!
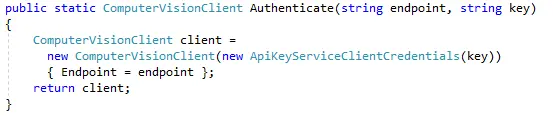
Let us have a quick look into the code on how we have used “Computer Vision” cognitive service

So, we have used “ComputerVision” cognitive service NuGet package to load the service and make use of it accordingly. Next step is to authenticate with the endpoint and the key and create a Computer Vision client, which will be later used for analysis and detection of objects.
We have a separate method where we are analyzing the images to extract captions, categories/taxonomy, tags, and brands. In addition to these details, we can also remove objects, faces, adult content, celebrities, landmarks, color scheme, and image types
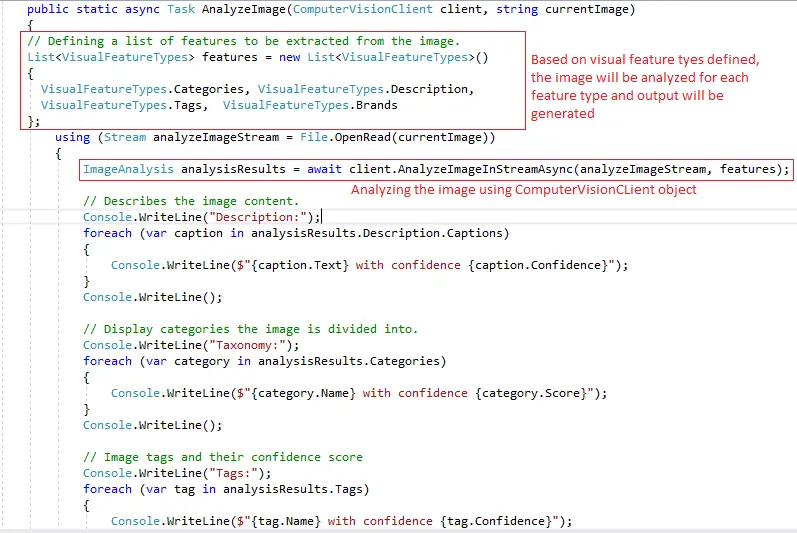
So, now we have high visibility on how to extract rich information, including text from images to enhance content searchability and create robust products and digital asset management tools by embedding computer vision capabilities in apps.
The significance of such technology becomes even more critical when businesses across industries are facing an increasingly competitive environment and are struggling to maintain higher profit margins. Advancements in computer vision are making the technology even more powerful and reliable than ever and enabling automation of more and more assets.





